Google, what happened!!?
When I discovered that Google has stopped indexing pages on my blog.
I was working again with Aspire this week and hit another issue launching the solution under Visual Studio. It felt familiar, but I wasn’t sure. A quick search online threw up some results, but nothing great.
Did I make a note of the error in OneNote? No.
What about my blog? Umm.. yes! And super embarrassing, it was my most recent post!
So yay! I applied the workaround and was unblocked. But that got me thinking.. surely my post should have been somewhere in the search results by now?
And that’s how I discovered that starting in mid-April Google suddenly decided to stop indexing pages on my site!
Here’s the summary from Google Search Console:
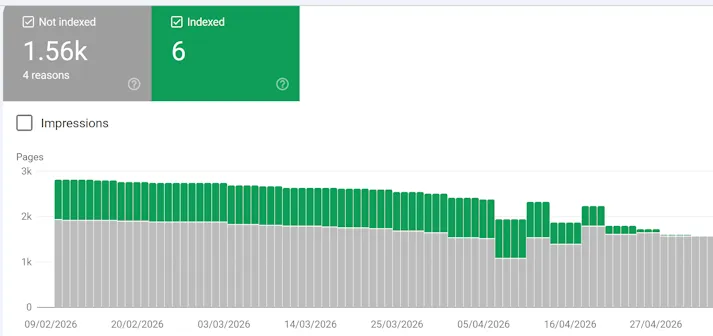
Only 6 pages currently being indexed? What on earth?
Scrolling further down that page and it breaks down why pages aren’t being indexed:
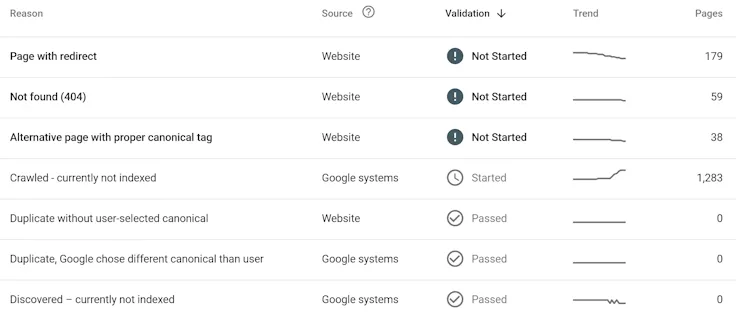
Pretty much all of my actual blog posts are under the ‘Crawled - currently not indexed’ category.
So for some reason (and they don’t really say why) Google knows about the pages, but has not included them in the index, so that’s why my search didn’t show up my blog post.
So what changed in April?
I looked back at the Git history of my blog repo. There were some changes I merged late March. The only thing that was slightly interesting was I did upgrade from Astro 5 to 6 during that time.
Looking at the source of the homepage, I noticed something curious:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="icon" href="/favicon.ico">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="generator" content="Astro v6.3.1">
<link rel="canonical" href="https://david.gardiner.net.au/index">
<link rel="sitemap" href="/sitemap-index.xml">
<title>David Gardiner</title> That ‘canonical’ line looks wrong! The href should be set to https://david.gardiner.net.au/, but it has a /index tacked on the end. I checked the canonical values for other pages, and they were all fine. So just the home page is wrong.
Out of interest, I switched back to the revision of the repo before that change and rebuilt the website at that point in time. Sure enough it was correct back then:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="icon" href="/favicon.ico">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="generator" content="Astro v5.18.1">
<link rel="canonical" href="https://david.gardiner.net.au/">
<link rel="sitemap" href="/sitemap-index.xml">
<title>David Gardiner</title>The code that created the canonical URL looked like this:
<link
rel="canonical"
href={new URL(Astro.url.pathname.replace(".html", ""), Astro.site)}
/>So it appears the functionality has changed in Astro 6 slightly. I created a new function that returns the correct value, including for the home page:
export function getCanonicalUrl(astroUrl: URL, astroSite: URL | undefined): string | URL | null | undefined {
const pathname = astroUrl.pathname.replace(".html", "");
if (pathname === "/index") {
return new URL("/", astroSite);
}
return new URL(pathname, astroSite);
}My blog site is rendered statically, and as a way of ensuring that no surprising changes to the generated HTML happen from component updates, I previously created a couple of snapshot tests using Verify CLI. In particular these check the contents of a specific blog post and also the RSS feed.
But I realised I didn’t have one in place for the home page. While that wouldn’t work well for my main blog repository (which is private), as the home page content would change every time I published a new blog post, that isn’t true for the public repo where I maintain the blog engine logic. There I have just a few old blog posts that i use for testing.
I’ve added that into the pipeline now, so that in the future if there are any unexpected changes from upgrades, the snapshot test will allow me to review them and decide if they are acceptable or not.
Now whether this is the actual cause of Google taking a dislike to me, I have no idea. But it’s the most obvious thing I can see so far. Time will tell if I get back in Google’s good books or not.
On the plus side, I did check with Bing’s Webmaster tools, and that all looks fine (and Bing is returning results for my site), so at least it isn’t everyone who doesn’t like me.