-
ADNUG Streaming struggles
Back in 2020, the Adelaide .NET User Group switched to a virtual-only format due to pandemic restrictions. When we returned to being able to meet in person in 2021, I was keen to maintain some of the connections we’d made while we were running online, particularly with folks who joined us from interstate and overseas, as well as Adelaide people who for any reason aren’t able to be in the room.
I already had a Microsoft LifeCam Studio Webcam (available as business or the more pricey regular models) which we’d used when video-conferencing with a remote speaker, and an MXL AC-404 boundary microphone that I’d been using for a few years to record audio for the group podcast.
I had some funds put aside for the user group as well as a generous donation, so I decided to put that towards some hardware to help with streaming our meetings. I bought the following gear:
- Elgato Game Capture HD60S+ screen capture (now superseded by the model X)
- Rode Wireless GO II USB wireless microphones.
Both of these are well-regarded brands so I felt confident that I had selected reliable products to use. If only that was the case.
First attempt
I did some testing at home and everything seemed to work ok and headed off to our April meeting. Having the two wireless mics would be handy as we had a presentation planned with two speakers.
I had brought two laptops - one to manage the stream and the other to present the introductory slides. But the Rode mics just refused to work. They were turned on, and the status on the receiver showed levels from the two transmitters, but nothing was showing up on the computer. A lot of fiddling, and rebooting to no avail. In the end, I had to resort to using the MXL boundary microphone. Unfortunately it didn’t work as well for picking up the presenters and people on the stream were having real trouble hearing.
Next month
The following month I’d done some further testing. I discovered that the Rode mics worked with my older laptop, but not the newer one. Not sure why, but I suspect there might be something a little odd with the USB audio on that device.
The next problem we hit was that the data projector didn’t seem happy having the Elgato capture device plugged in. The display in the room we normally use is a multi-screen wall display (so not an actual projector).

We’ve had issues with this display in the past, even before we tried streaming. Some laptops just didn’t like it (they’d display for a few seconds, then the screen would go blank). It was so bad we ended up having to do a screen share from the speaker’s laptop to another laptop that was known to work with the display. I’m guessing there’s some kind of signal strength issue, but it is hard to know for sure. We use a room at the University of South Australia, and the equipment probably gets a fair bit of wear and tear.
I ended up removing the capture device and not streaming that month.
And then
In the months that followed we tried various combinations and managed to get the stream to work, but there was always the uncertainty of not knowing until the last minute whether it was going to work correctly or not.
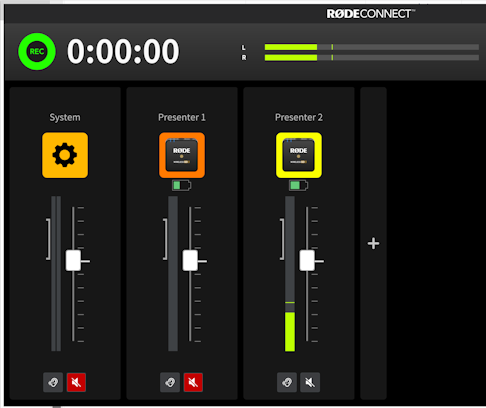
The audio was refined a bit by making use of the Rode Connect application to allow the mixing/muting of the two wireless mics. Much easier to mute the mics remotely, rather than having to ask the presenters to turn their mics on and off. The only downside is that the audio from Rode Connect comes into OBS Studio as a single channel, rather than two separate ones.
Working on the theory that the video signal strength might be the problem, I wondered if an HDMI signal amplifier might help. I bought a StarTech.com HDBOOST4K 4K 60Hz HDMI Signal Booster and tried it out. It did seem to provide a bit more stability, but that element of doubt remained. One issue that remained was that switching presenter laptops would still interrupt the signal. The Elgato seemed to need a power cycle to cope with the change.

So we had something that worked, but it could be better.
Next steps
Late last year I happened to be watching the live stream from Brisbane .NET User Group’s meeting and was able to ask them how they manage their broadcast. From memory, they just had a large-screen TV in the room, so didn’t have the challenges we experienced with room display. But also differently, rather than trying to capture video with a passthrough device like the Elgato, they use a video splitter to send the signal to both the TV and a separate capture device. The capture device they use is similar to this HDMI to USB-C Type-C Video Capture Card.
So now I’ve bought the following to try out at the next meeting:
- Simplecom CM412 HDMI 2 Port HDMI Duplicator
- 4K HDMI USB-C Capture Card (similar to the model above).


I’m not sure how the HDMI splitter will go - I fear the multi-screen display might not like it either, but it’s worth a shot, and they’re not that expensive.
The fallback option is to drive the multi-screen display from the streaming laptop’s external display. We use OBS Studio for streaming so the idea would be to map the output preview to the external display. In this way, the room display will have a constant signal, and in theory, we can switch input laptops without annoying the room display.
As an aside, one other positive is that my latest laptop does work correctly with the Rode mics.
Future thoughts
One challenge that remains is having to switch between different scenes in OBS Studio and also muting and unmuting the mics. Something like an Elgato Stream deck might make that easier (instead of needing to alt-tab between OBS and Rode Connect applications).

It would also be nice to have a better solution for in-person audience questions. We do have the MXL boundary mic, but a handheld mic would give clearer audio. Something for the wishlist!
If Rode ever updated Rode Connect to provide separate audio channels, that would be nice too.
I’ll write a follow-up post down the track to report on how everything went. Check out the meeting recordings on our YouTube channel too.
(Amazon links are affiliate links.)
-
3 years at SixPivot
A month down already in 2024, which means it’s my 3rd anniversary at SixPivot!

I’m pleased to report things continue to go well on the work front. Working for a remote-first company really does suit me. Here I sit (or sometimes stand) at my desk at home, looking out at my garden and to the hills beyond. My morning commute is (depending on the weather) a 5km walk around the neighbourhood, or if I’m feeling inspired a 20km bike ride. As long as there aren’t too many meetings (which isn’t that common for me) then being able to focus without distractions is very valuable.
It is also so good to have the depth and variety of expertise to draw on with my colleagues. That is a real highlight and something I lean on pretty regularly. I try to repay the favour when I can too. There’s a positive shared sense of humour across the company too - I think that’s also a healthy sign.
Even though we all work remotely, it is extra special when we do catch up in person. That has happened over the past 12 months, with both me travelling interstate a few times, and also when we had an impressive contingent of Pivots in town for DDD Adelaide 2024 in November.
Another nice thing about having a work anniversary at SixPivot (aka ‘workversary’!) is you are given a bunch of ‘good vibes’ points to spend in the rewards shop.
I’m looking forward to seeing what the next 12 months at SixPivot brings.
-
Source Link improvements in .NET 8 SDK
One enhancement included in the .NET 8 SDK you might have overlooked is that if you’re using GitHub, GitHub Enterprise, Azure Repos, GitLab 12.0+, or Bitbucket 4.7+ then you no longer need to add a package reference to the respective
Microsoft.SourceLink.*NuGet packages to get source link support.
Find out more about Source Link in the NuGet documentation
If you’re using a tool like Dependabot to keep your NuGet packages up to date, you might see a pull request with a title similar to this:
Bump Microsoft.SourceLink.GitHub from 1.1.1 to 8.0.0
That could be a hint that if you ensure .NET 8 SDK is being used to build the project then you can remove the
Microsoft.SourceLink.GitHubpackage reference, rather than just accepting the pull request. One less package to maintain, but still the same debugging experience for users of your package.Check out the README in the Source Link repository on GitHub for more information.

A blog of software development, .NET and other interesting things