-
Source Link improvements in .NET 8 SDK
One enhancement included in the .NET 8 SDK you might have overlooked is that if you're using GitHub, GitHub Enterprise, Azure Repos, GitLab 12.0+, or Bitbucket 4.7+ then you no longer need to add a package reference to the respective
Microsoft.SourceLink.*NuGet packages to get source link support.
Find out more about Source Link in the NuGet documentation
If you're using a tool like Dependabot to keep your NuGet packages up to date, you might see a pull request with a title similar to this:
Bump Microsoft.SourceLink.GitHub from 1.1.1 to 8.0.0
That could be a hint that if you ensure .NET 8 SDK is being used to build the project then you can remove the
Microsoft.SourceLink.GitHubpackage reference, rather than just accepting the pull request. One less package to maintain, but still the same debugging experience for users of your package.Check out the README in the Source Link repository on GitHub for more information.
-
Azure Function posting an RSS feed to Mastodon
Twitter (or 'X' as it seems to be called now), to my surprise, hasn't died yet. I'm still there, but I must say I'm enjoying the discussions over on Mastodon a lot more (follow me at https://mastodon.online/@DavidRGardiner). But there are a few feeds that I follow on Twitter that I'd like to follow on Mastodon. So I wrote a little Azure Function to do that for me (and anyone else who is interested).
One that is relevant to living in South Australia, especially over the warmer months, given where I live is a bushfire-prone area, is keeping an eye on the updates from the Country Fire Service (known locally as the CFS). They have a Twitter account, but not a Mastodon account. If only there was a way to get their updates on Mastodon!

As it turns out, the CFS publish some RSS feeds. My first attempt was to make use of a service like Mastofeed, which in theory can take an RSS feed and post updates to Mastodon. But as I discovered, the RSS feed from the CFS has a few oddities that seem to prevent this from working correctly - it posted one update but then stopped. Here's an example of the RSS feed:
<?xml version='1.0' ?> <rss version='2.0' xmlns:atom='http://www.w3.org/2005/Atom'> <channel> <atom:link href='https://data.eso.sa.gov.au/prod/cfs/criimson/cfs_current_incidents.xml' rel='self' type='application/rss+xml' /> <ttl>15</ttl> <title>Country Fire Service - South Australia - Current Incidents</title> <link>https://www.cfs.sa.gov.au/incidents/</link> <description>Current Incidents</description> <item> <link>https://www.cfs.sa.gov.au/incidents/</link> <guid isPermaLink='false'>https://data.eso.sa.gov.au/prod/cfs/criimson/1567212.</guid> <title>TIERS ROAD, LENSWOOD (Tree Down)</title> <identifier>1567212</identifier> <description>First Reported: Saturday, 06 Jan 2024 15:41:00<br>Status: GOING<br>Region: 1</description> <pubDate>Sat, 06 Jan 2024 16:15:03 +1030</pubDate> </item>There is the
identifierelement that is non-standard, but I suspect the main issue is theguidelement. For some reason, theisPermaLinkattribute is set to false. On the face of it, that looks like a mistake. That URI (which incorporates the identifier value) does appear to be unique. WithisPermaLinkset to false, it hints that the value can't be used as a unique identifier. I'm guessing because of that, Mastofeed had no way to distinguish posts in the RSS feed.So we're out of luck using the simple option. My next thought was whether there was something that could transform/fix up the RSS on the fly - an 'XSLT proxy' if you like, but I've not found a free offering like that.
Maybe I can write some code to do the job instead. Hosting it in an Azure Function should work, and ideally would be free (or really cheap).
An Azure Function
I ended up writing a relatively simple Azure Function in C# that polls the RSS feed every 15 minutes (as that's the value of the
ttlelement). It then posts any new items to Mastodon. Here's the code (Link to GitHub repo):[Function(nameof(CheckAlerts))] public async Task<List<CfsFeedItem>> CheckAlerts([ActivityTrigger] List<CfsFeedItem> oldList) { var newList = new List<CfsFeedItem>(); var response = string.Empty; try { using var httpClient = _httpClientFactory.CreateClient(); response = await httpClient.GetStringAsync( "https://data.eso.sa.gov.au/prod/cfs/criimson/cfs_current_incidents.xml"); var xml = XDocument.Parse(response); if (xml.Root.Element("channel") is null) throw new InvalidOperationException("No channel element found in feed"); var xmlItems = xml.Root.Element("channel")?.Elements("item").ToList(); if (xmlItems is not null) foreach (var item in xmlItems) { var dateTime = DateTime.Parse(item.Element("pubDate").Value); newList.Add(new CfsFeedItem( item.Element("guid").Value, item.Element("title").Value, item.Element("description").Value, item.Element("link").Value, dateTime )); } // Find items in newList that are not in oldList var newItems = newList.Except(oldList).ToList(); if (newItems.Any()) { var accessToken = _settings.Token; var client = new MastodonClient(_settings.Instance, accessToken); foreach (var item in newItems) { var message = $"{item.Title}\n\n{item.Description.Replace("<br>", "\n")}\n{item.Link}"; _logger.LogInformation("Tooting: {item}", message); #if RELEASE await client.PublishStatus(message, Visibility.Unlisted); #endif } } else { _logger.LogInformation("No new items found"); } } catch (Exception ex) { _logger.LogError(ex, "Problems. Data: {data}", response); } return newList; }We keep a copy of the previous list of items, and then compare it to the new list. If there are any new items, we post them to Mastodon. Because we need to remember the previous run items, we need to use Durable Functions. This was my first time creating a Durable Function, so that also made it a good learning experience. The 'eternal orchestration' pattern is used, where the orchestration function calls itself, passing in the new list of items. Here's the orchestration function code:
[Function(nameof(MonitorJobStatus))] public static async Task Run( [OrchestrationTrigger] TaskOrchestrationContext context, List<CfsFeedItem> lastValue) { var newValue = await context.CallActivityAsync<List<CfsFeedItem>>(nameof(CfsFunction.CheckAlerts), lastValue); #if RELEASE // Orchestration sleeps until this time (TTL is 15 minutes in RSS) var nextCheck = context.CurrentUtcDateTime.AddMinutes(15); #else var nextCheck = context.CurrentUtcDateTime.AddSeconds(20); #endif await context.CreateTimer(nextCheck, CancellationToken.None); context.ContinueAsNew(newValue); }The Durable Function infrastructure handles serialising and deserialising the list of items automatically. The Function takes a parameter that receives the list from the previous run. When the function completes, it returns the list that will be passed to the next run. The orchestration function passes in the list and sets things up to save the list so that it can be passed to the next run.
One thing about this pattern is you need some way of kickstarting the process. The way I chose was to add a HTTP trigger function that calls the orchestration function. The release pipeline makes a call to the HTTP trigger endpoint after it publishes the function.
Durable + .NET 8 + isolated
The Durable Function targets .NET 8 and uses the isolated model. It was a little challenging figuring out how to get this combination to work, as most of the documentation is either for the in-process model or for earlier versions of .NET. Ensuring that the appropriate NuGet packages were being referenced was tricky, as there are often different packages to use depending on the model and version of .NET. I ended up using the following packages:
<PackageReference Include="Mastonet" Version="2.3.1" /> <PackageReference Include="Microsoft.Azure.Functions.Worker" Version="1.20.0" /> <PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.DurableTask" Version="1.1.0" /> <PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.Http" Version="3.1.0" /> <PackageReference Include="Microsoft.Azure.Functions.Worker.Extensions.Timer" Version="4.3.0" /> <PackageReference Include="Microsoft.Azure.Functions.Worker.Sdk" Version="1.16.4" /> <PackageReference Include="Microsoft.Extensions.Configuration.UserSecrets" Version="8.0.0" />Costs
To keep costs to a minimum, the Azure Function is running on a consumption plan. The intention is to keep it close to or under the free threshold.
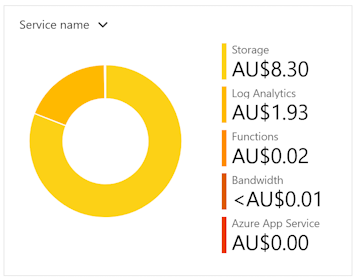
As it turns out, so far the Function is not costing very much at all. It's actually the Storage Account that is the most significant. AUD8.30 so far and the total forecast for the month will be AUD17. An Azure Function needs to be linked to a Storage Account. It would be interesting to see if there are any changes I could make to reduce the cost further.
To see the latest posts from the Azure Function, you can go to https://mastodon.online/@CFSAlerts (and if you're on Mastodon, feel free to follow the account!)
Future enhancements
Apart from seeing if I can reduce the cost even more, the other thing that would be useful is to also track the daily fire bans. This data is published as an XML file, so parsing that once a day should be pretty straightforward.
You can find the full source code for the Azure Function in this GitHub repo.
-
Apple TV 4K with Ethernet
At SixPivot we have a concept of 'Good Vibe' points. You can give points to colleagues as a way of saying thanks for something they've done. Points you've received can be spent in our internal Rewards shop. I previously used points to top up my laptop allowance when purchasing my latest laptop. More recently I used points to purchase an Apple TV 4K via some JB HiFi gift cards.

We have just one TV in the house. It's an LG Smart TV (2014 model), so it is getting on in years. But it still works, though the number of apps it runs has reduced over time. The free-to-air TV stations in Australia all have streaming apps for smart TVs and mobile devices, but only ABC and SBS had apps that worked on this model, and SBS dropped support earlier in the year. Netflix still works on the TV, but Disney+ doesn't, so we've been using the Xbox One for that. But those free-to-air apps aren't on XBox either.
While we don't currently own any Apple desktops or laptops, we do have iPhones and iPads (largely because back in the day the kids' schools required them to have iPads), and we've stuck with that ecosystem. And so with Christmas approaching, I settled on the idea of buying an Apple TV device. I opted for the 4K model with 128GB of storage and an Ethernet port. Our TV isn't 4K but probably one day we will get one that is, and I do have Ethernet running to where the TV lives in the house, so it made sense to take advantage of that (and the extra storage).

I'd bought it a few weeks before Christmas and had hidden it away, so actually only remembered it later on Christmas day. The family were at first a bit bemused by my choice. "But what does it do?" they asked.
Setting it up was quite straightforward - I used my iPhone to configure it and we were up and running in a few minutes. And yes, even though it is a '4K' model, it works just fine with a regular HD TV.
But the clincher was installing the free-to-air apps. SBS, ABC TV, 7Plus, 9Now and 10Play all work. And having easy access to many of the TV series that family members enjoy was an 'Ah Haa!' moment.
It also runs Netflix and Disney+, and being a more modern device, also runs them faster and more responsively than the TV ever could.
Having all the streaming services in one place is very convenient. The remote is simple but usable. Time will tell how robust it is (to survive being accidentally dropped on the floor).

One nice surprise - using the remote control to turn off the Apple TV device also turns off the TV. (You still need the TV remote to turn it on again though). The volume buttons also directly control the TV volume (not just the Apple TV volume).
The 'Home' button is a bit surprising. By default seems to take you to the Apple TV+ screen (Apple's own streaming service). Actually, that might explain why Apple doesn't call it a 'Home' button but the 'TV' button. I just discovered that you can change the behaviour via Settings so that it does take you to the home screen - a much more sensible setting.
Usually when you're searching for content you need to peck away with the remote selecting letters from the alphabet (and most of the Apple TV apps display a single-line alphabet rather than a keyboard layout). However, I discovered that if you have your iPhone handy, you can use the iPhone keyboard to enter the search text, which is much quicker than using the remote.
You get a 3-month trial of Apple TV+, so given it's the Christmas holidays we've taken advantage of that. At this stage I'm not sure we'd pay for it once the trial is over - it would need to replace Netflix or Disney+ if we did.
So far, so good and the family seem to have adapted to it quickly.
Apple TV 4K + Ethernet (affiliate link)

A blog of software development, .NET and other interesting things